
I Built a Medical SaaS With AI. Then I Got Hacked. Here's the Case Study.
The first night I deployed my sister’s medical scheduling system to production, I went to bed feeling like a king. By 9am the next morning, my server’s CPU was pinned at 300%, and someone else was mining cryptocurrency on my rented hardware.
That’s the middle of the story, though. Let me back up.
This is a case study about the SaaS I always wanted to build, the one that finally found me, and everything I broke and learned getting it to work. It’s also the story of a Product Designer who thought he understood software, and discovered the internet is a much stranger, more hostile place than any Figma file ever suggested.
A quick note before we start: all the data shown in this post is fake. The screenshots are here to illustrate how the system looks today, nothing more.
ArturoMed’s module sidebar. Every item here is wired to every other piece of the system.
1. A Problem I Didn’t Know I Was Looking For
I’d been circling the idea of a SaaS for years. Everyone in the tech-adjacent internet talks about it: build the product, earn your MRR (Monthly Recurring Revenue), retire on compound growth. But I never had a problem worth solving. Ideas kept coming and going, and none of them felt like mine.
Then I had a long conversation with my sister, Dra. Paola Ruiz.
She has 1.7 million followers on TikTok as @bethruizmed. She’s a doctor. For reasons tied to both her audience and the Ecuadorian healthcare system, she started offering online advisory sessions on sexual and reproductive health. Because it’s advisory work, not diagnostic clinical practice, she can support people across many countries, not just Ecuador. Turns out there’s a real gap there, both in public education and in access to a doctor who won’t charge you a week’s salary for thirty minutes. Worth noting: general practitioners in Ecuador have a notoriously rough time finding stable work, so this kind of independent practice is also a way to rebuild a career on your own terms.
She found the problem, she solved it, and it was working.
Until it wasn’t.
Not in the business sense. The business was thriving. But she hit the first ceiling every successful solo operator hits: success without systems collapses on itself. She’s a great doctor. She is not a project manager. She is not running ops. Every appointment booking, every payment confirmation, every follow-up was living inside WhatsApp Business threads. She was drowning in her own pipeline.
Eventually she hired my other sister, Dra. Isabel Ruiz, also a doctor, as a part-time operations hand. Effectively a secretary, just to keep her head above water.
That’s when I stepped in. I made an offer: “What if we stop putting out fires with WhatsApp and I build you the system instead?”
I’d built her website months earlier. The leads were already flowing in. Automating the pipeline was the obvious next move.
2. The Four Pillars of Any Real Product
Before I wrote a line of code, I forced myself to think about the shape of what I was building. One thing I’d picked up somewhere along the way: every real product has roughly four or five essential components.
- A frontend. What the user actually touches.
- A backend. The logic that decides what happens.
- An authentication system. So people are who they claim to be.
- A payments system. Because this is a business, not a hobby.
- A database. Because nothing matters if it doesn’t persist.
This sounds obvious. It isn’t. Most “AI-built MVPs” you see online are half of a frontend with a pretend backend and zero persistence. They demo well and die the moment a second user shows up. If you want to ship something real, all five pillars need to be standing at once.
My sister paid my Claude Pro subscription ($100 a month) and I put it to work. Hard.
Technical choices
I refactored her existing website into React, then built the backend in TypeScript with Postgres. Standard stack, nothing exotic. The more interesting choice was infrastructure: I decided to bundle the entire application (frontend, backend, database) inside a single Docker container with three logical parts.
This is not what most tutorials tell you to do. Most tutorials push you toward microservices, a managed database, and some orchestrator. For a private deploy like mine, that’s overkill and a maintenance tax. One container meant one deploy, one backup, one thing to reason about. It kept me moving.
Along the way I picked up a lot I didn’t know I needed to learn: running [[Claude Code]] with background agents, structuring a real test suite, separating environments, thinking about migrations as a first-class concern. I was learning in public, with the stakes of a real user who expected the thing to work.
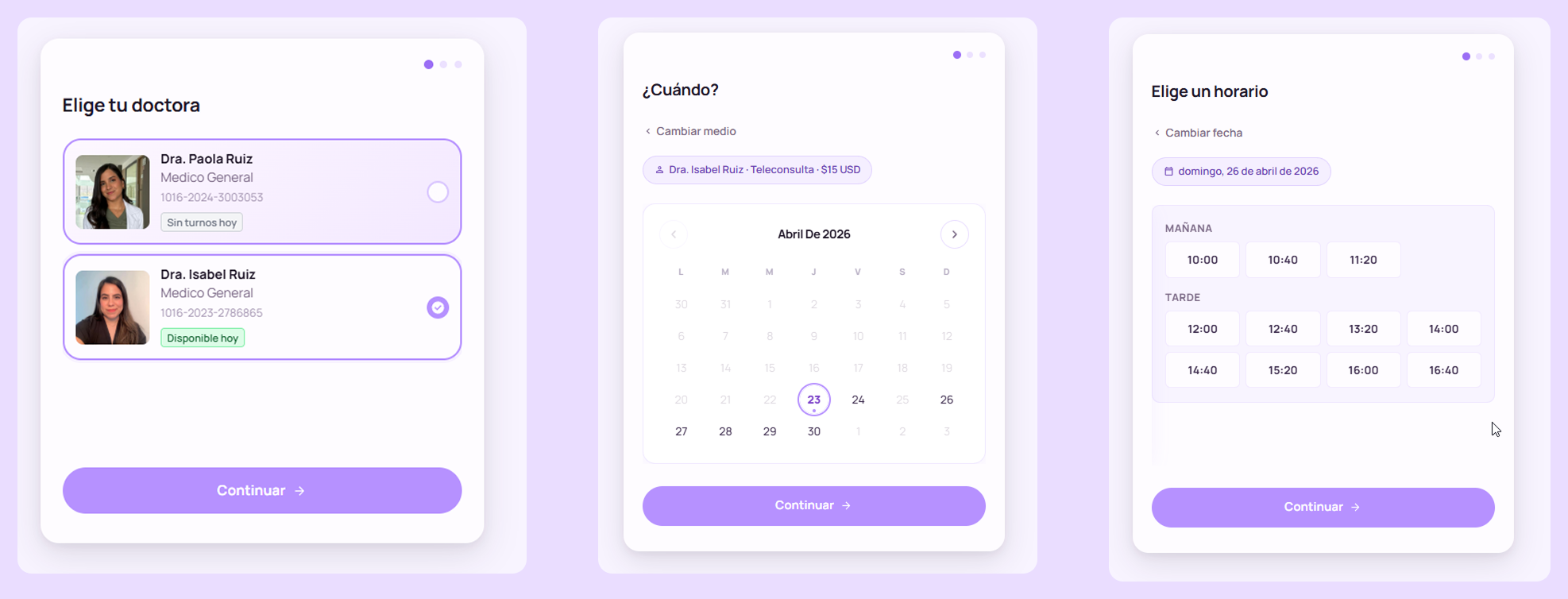
The appointment flow. The thing I actually cared about shipping. Getting to this point meant fighting everything described in the next section.
3. The Night I Got Hacked
The system reached “more or less functional.” I ran it through a weekend of manual testing. I was proud of it. It was the closest thing to a real product I’d ever built with my own hands.
I deployed to production. Because the system is private (only for her), I didn’t expect much drama. I went to bed.
The next morning, I checked the server dashboard. The CPU was running at 300%. It had been at 300% for eleven or twelve hours straight.
Now, I’m a genius of information security (not really). I had no idea what was happening. So I pointed Claude at the server logs and processes and asked it to figure out what the hell was going on.
The diagnosis came back fast: someone was running a crypto miner on my server. Monero, specifically. They were using my CPU to print money for themselves, and my hosting bill was paying the electricity.
But the interesting part wasn’t the miner. It was how they got in.
The real cause: Next.js had a critical security hole, and someone on the internet found it.
Next.js is the framework my dashboard runs on. The version I had deployed contained a known, documented bug that let anyone on the public internet send a specially crafted request and run their own code on my server. No password. No account. No stolen credentials. Just knowing the address of the server.
Security holes like this get rated on a scale from zero to ten for how dangerous they are. Mine was a ten. The patch had been out for weeks. I wasn’t on the patched version.
The attack. Minutes after I brought the server online, something on the internet started poking at it. First some reconnaissance to figure out what software was running. Then, seconds after confirming I had the vulnerable version, it fired the exploit. In under a minute, the crypto miner was alive inside my container, running as the highest-privilege user, burning CPU for someone else’s wallet.
That’s why the CPU was pegged for eleven hours while I slept.
The three things I got wrong.
First, I assumed the AI writing my code would pick the latest safe versions of the frameworks it used. It didn’t. It picked older versions that were genuinely published by Vercel, the company behind Next.js, but were already flagged with known security holes the company had asked everyone to upgrade away from. “Genuine” and “safe” are not the same word.
Second, my deploy pipeline was building the software directly on the production server. It was the easy way to ship, but it meant the build and the live app lived on the same machine. Anything malicious that executed during a build had the same access as the live app itself: database passwords, API keys, everything.
Third, my build wasn’t strict about versions. It could quietly use versions different from the ones my code was tested against, which is a reliable way to drag in changes you did not ask for. Not how this particular attack landed, but a door left open for the next one.
Three mistakes. One known hole. Eleven hours of somebody else’s crypto mining. One very annoyed morning.
[!warning] Running unpatched software on the internet is the attack If there’s a known security hole in any piece of your stack and you’re on a version without the fix, everything else is noise. The Dark Forest finds you by scanning every IP on the internet in a loop. The time between “my server is live” and “someone is testing known exploits against it” is measured in hours. Patch first. Everything else second.
4. Rebuilding With Scars
I spent the next two days doing what I should have done on day zero. The list got long fast.
Patch Next.js, everywhere, same day. Both versions in my stack (the dashboard on 15.2.3, the marketing site on 14.2.35) jumped to 16.2.4, which patches CVE-2025-55182. The fix is the upgrade.
Rotate every credential the container touched. Database password, NextAuth secret, Google service account private key, Google OAuth client secret, Resend API key, cron secret. If the miner ran as root inside the container, /proc/1/environ was readable. Every env var is leaked.
npm install is banned in Dockerfiles. Replaced with npm ci, which fails the build if package.json and package-lock.json disagree instead of silently resolving a different dependency tree.
Containers drop to a non-root user. A new app user runs before CMD. When the next RCE hits (and one always eventually does), the attacker lands in a shell that can’t touch root-owned processes or the host filesystem.
Geo-blocking at the firewall. Paola’s audience is the Americas and some of Spain, so ports 80 and 443 are blocked for everywhere else. About 50,000 CIDRs allowed via ipdeny feeds, the rest of the planet denied. Probing traffic dropped 90% overnight.
Malicious IP blocklist. Feeds from FireHOL Level 1, Spamhaus DROP, and Feodo Tracker pulled daily. About 4,500 IPs actively attacking other people’s infrastructure right now don’t get to reach mine.
nginx rate limits per endpoint. Login at 5 req/min, public API at 30 req/s, general pages at 20 req/s. A brute-force probe hits the cap in seconds.
fail2ban, three jails. One watches nginx logs for the Server Action RCE IOC (Failed to find Server Action), one for rate-limit violations, one for SSH. First hour after redeploy, three IPs already banned.
npm audit --audit-level=high gates the deploy. Any high-severity CVE in any dependency blocks the pipeline. Green audits are a requirement, not a notification.
Dependabot enabled. Weekly PRs for npm, monthly for Docker and Actions. Versions check themselves and open pull requests against me.
Build off the production box. The pipeline now compiles on an ephemeral GitHub Actions runner, runs tests, runs npm audit, and only then pushes a Docker image. The server’s only job is docker pull, restart, and run SQL migrations if the schema changed. Nothing else.
That last one is the change I most want to underline. When you separate the build environment from the runtime environment, you contain the blast radius of a compromised dependency. Supply-chain attacks still happen, but they execute inside a throwaway runner that gets nuked after every build, not inside the machine holding your production secrets.
The Dark Forest
If you’ve read The Three-Body Problem by Liu Cixin, you know the Dark Forest theory. In the book, the universe is full of civilizations that stay silent because announcing your presence is an invitation to be destroyed. Everyone is listening. No one wants to be heard first.
The internet is the Dark Forest.
The noise you never hear from inside your cozy localhost is the noise of millions of bots and scanners pinging every IP, every exposed port, every known service signature, looking for someone careless. The moment you expose something that looks misconfigured, something out there notices.
I had a $20/month server. It was hit within hours of going online.
Now imagine the attention your server gets if it’s running on 200GB of RAM and looks juicy. The Dark Forest is not metaphorical. It’s operational reality, and anyone shipping something to a public IP should treat it that way from day one.
The calendar module with time blocking. The unsexy backbone of any working scheduling platform.
5. The Kimi 2.6 Night
A few weeks after the cryptominer incident, with the system stable, hardened, and running quietly in production, something unexpected landed on my lap.
Cline was offering free access to Kimi 2.6, the coding agent from Moonshot. From what I’d read, it punches surprisingly close to Opus 4.6 on certain task classes at a fraction of the cost. For a system like mine, where the architecture was already set and I mostly needed volume of scaffolding, not deep architectural decisions, it looked worth a shot.
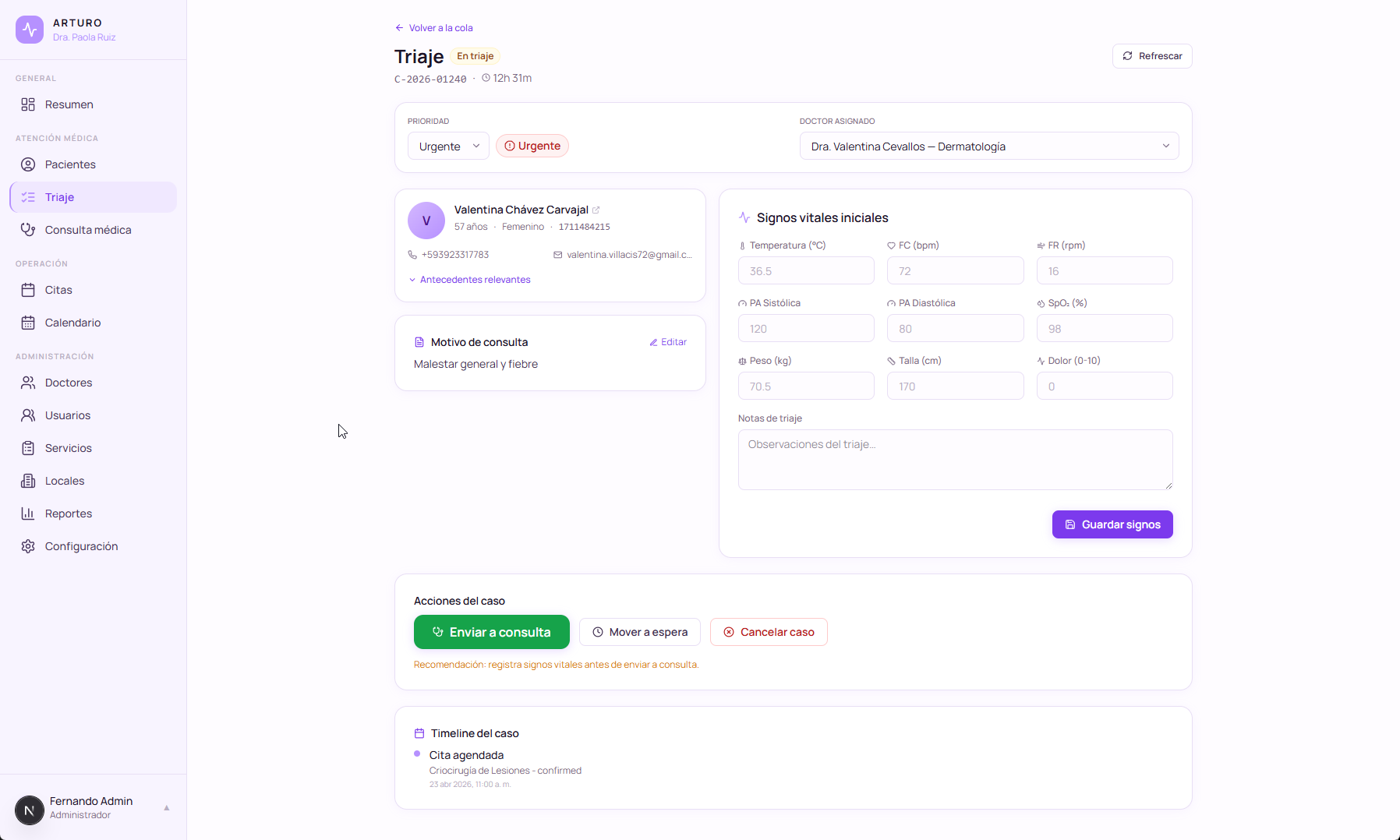
I opened a new branch. I gave the agent the full permission set: file system, package install, execute, everything. I told it what I wanted: not another scheduling tool for a single doctor, but a full operations platform for a small clinic. Overview dashboard, appointments, calendar, doctors, services, locations, reports, configuration, and on top of that the clinical surface: patients with history, nurses, triage. Every module wired to every other. Then I went to sleep.
I woke up to a working system. I named it ArturoMed, after my grandfather Arturo.
Not “a prototype.” Not “a skeleton.” ArturoMed had the modules implemented, schemas laid out, routes wired between them, roles separated, and enough structure that I could spend the next couple of days with Claude refining the sharp edges instead of writing the bones from scratch.
And the point of ArturoMed is not that each module exists in isolation. The point is that they talk to each other. A doctor’s profile links to the services that doctor offers, to the locations where they practice, to the calendar slots they have blocked, to the reports that summarize their month. A service links to the locations that host it and to the doctors who deliver it. The calendar aggregates across doctors and locations. Reports slice by any dimension you care about. ArturoMed is designed for a clinic, not for a single practitioner.
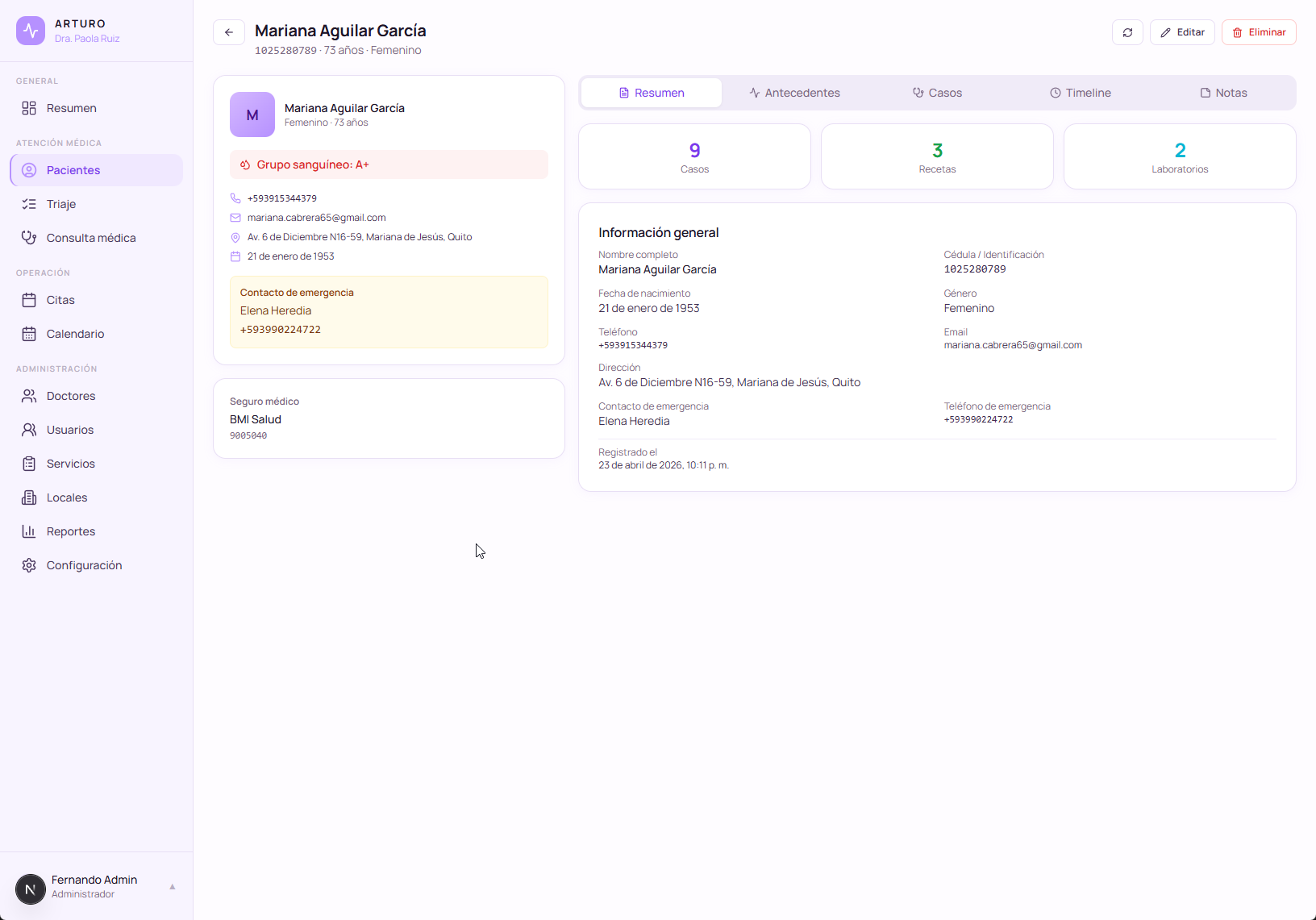
The patient module with clinical history, built overnight and refined over the following week. One module of ArturoMed, wired to everything else in the system.
At this point I could reasonably walk up to a small practice today and say: “Here is a complete operations platform. Run your clinic on it.” And it would hold up.
But I’m not shipping the clinical half to anyone yet. Not even to Paola. Here’s why.
What Paola actually has running in production is only the auto-scheduling layer. Patients book appointments through her website, the system confirms, the calendar updates, and that’s it. No clinical history, no triage notes, no sensitive medical data. Just appointment times and basic contact info. ArturoMed lives in a branch on my laptop, waiting.
Medicine is one of the most regulated domains on earth, and Ecuador rolled out its Data Protection Law in the last couple of years, similar in spirit to GDPR, adapted to our context. The privacy constraints around patient data are serious, and “I built this in a weekend with AI” is not a defense when a patient’s clinical history leaks. On top of the data law, as far as I understand, there is also a formal process with Ecuador’s Ministry of Public Health (MSP) for any platform that manages clinical records, which is its own multi-month conversation.
So right now I’m in the compliance layer. Access controls. Audit logs. Data encryption at rest. Retention policies. Role separation between doctor, nurse, and admin views. The work that does not look glamorous in a demo video but determines whether a product is legally allowed to exist. The clinical modules ship to Paola only when that work is done and the regulatory picture is clear.
6. What I Actually Learned
This is the part of the case study I’d want someone else to tell me, so let me try to be honest about it.
A deep respect for pre-AI developers
I’m now sitting on something like 20,000 to 30,000 lines of code for what is, in essence, a glorified Excel sheet with a calendar attached. I built this with AI accelerating me at every step. And I still found it huge.
If this is what it takes for a small scheduling platform, what does it take to run a hospital? Inventory, labs, pharmacy, payroll, emergency workflows, multi-location, multi-specialty, legacy integrations. I used to look at enterprise medical software and think it was bloated. I don’t anymore. I think the people who maintain it deserve a standing ovation.
localhost is a lie
Everything works on localhost. Everything.
The minute you put it on the internet, with real users, real authentication, real network latency, real attackers, you discover how much your development environment was protecting you. The jump from “it works on my machine” to “it works in production for other humans” is the jump most AI-built projects never actually make.
Vibe coders, learn RLS
If you’re vibe-coding a SaaS with a shared database, you have to understand Row Level Security. Without it, any authenticated user can potentially query any other user’s data. This is not a theoretical concern. It’s the default behavior of most database setups unless you explicitly configure permissions.
RLS is the difference between “every user sees their own data” and “welcome to the class-action lawsuit.”
Not every npm install is safe
Think twice before running npm install on anything that doesn’t come from a package you’d personally vouch for. Supply-chain attacks are real and accelerating. The cryptominer that hit my server didn’t arrive through a phishing email. It arrived through a transitive dependency of a major framework, invisible to anyone not specifically looking for it.
This is the part of modern development nobody wants to talk about, because it undermines the whole “move fast, import everything” ethos. But it is the reality.
Playwright changed my testing life
The last lesson is more operational than security. I used to let AI test my app by driving a browser through MCP (Model Context Protocol). It worked, but it was wildly expensive. Each UI step ate tokens, and a full test run could burn through a serious chunk of my daily context budget.
Then I learned Playwright, the browser automation framework. It tests everything (every button, every API call, every state change) on a schedule, without an LLM in the loop. I now have automated end-to-end tests that run across the entire system, while the LLM is reserved for the tasks that actually need intelligence.
Before Playwright, testing felt like Claude’s side quest that drained my main quest budget. After Playwright, testing became infrastructure.
[!important] The pattern under all of this AI opens doors. It does not replace rigor. It exposes you to a surface area (security, infrastructure, compliance) you would not have needed to think about as a designer before. The discipline is knowing that the surface exists and choosing to learn it.
Where the system stands today. Compliance work still in progress, but operationally complete. All data shown is synthetic.
7. Where This Goes Next
Both sisters are noticeably calmer these days. Paola isn’t drowning in scheduling anymore. Isabel isn’t burning out chasing WhatsApp threads. Clients book themselves through the website, the system confirms automatically, the calendar reflects reality. They have CRUD on the pieces they actually need (appointments, services, availability windows), plus time-blocking for when either of them needs to be off the grid. None of this touches medical data: the live version is the auto-scheduling layer only, precisely because compliance isn’t done.
The shape of the team has also changed along the way. Isabel started as administrative support, but with scheduling running itself she now has time to take her own advisory sessions, and she covers Paola’s slots when Paola can’t. She’s just starting to build her online presence, so if you want to follow a doctor actively building her practice, @draisabelruiz on Instagram is where she’s showing up.
The milestones I’m excited about come next, waiting on the compliance and MSP picture to resolve: clinical history search, automated reminders, smarter messaging, and probably AI-generated session summaries for the doctor to review (not to replace her judgment, just to save her thirty minutes a day on documentation).
If I had to compress this whole story into one sentence for another designer thinking about building something real, it would be this:
Be curious.
Be curious about the technology sitting underneath your interfaces. Be curious about what actually makes a system secure, not just what makes it pretty. Ask your developers how it works. Ask them what breaks. Ask them what they’re scared of in production. Understand the pipeline end to end. Because designers are closer than we’ve ever been to being able to ship full products, and the gap between “I can design this” and “I can ship this” is now mostly about whether we’re willing to learn the machine.
This is probably not my magnum opus. I’m too early in my career to call anything that. But it’s the proudest thing I’ve shipped so far, and it’s the first thing I’ve built that changed the operational reality of people I love.
The screenshots in this post show the system populated with synthetic data, because the real data belongs to real patients, and the whole point of the compliance work is that you never see it.
If you’re a company or a solo operator looking for a Product Designer with real UX/UI experience and a taste for shipping things that actually run in production, I’m open to contracts. LinkedIn is the best place to reach me.
Hire me on LinkedIn →And if you want to learn the techniques I use, how I operate between design, AI tooling, and shipping real systems, I teach a workshop with Xperience, a training company here in Ecuador that specializes in UX and Product education. The last cohort left with some of the best testimonials I’ve ever received.
Join the workshop →