Loop Engineering: Deja de Promptear Agentes, Empieza a Diseñar el Sistema que los Promptea
Durante dos años, la forma de sacarle algo útil a un agente de código era simple: escribir un buen prompt, compartir suficiente contexto, leer lo que devolvía, escribir lo siguiente. El agente era una herramienta y tú la sostenías todo el tiempo, un turno tras otro. Tú eras el loop. Cada ciclo pasaba por tus manos y tu atención.
Esa parte está terminando. No el pensar. El escribir.
Boris Cherny, quien lidera Claude Code en Anthropic, lo dijo sin rodeos: “Ya no le hago prompts a Claude. Tengo loops que le hacen prompts a Claude y deciden qué hacer. Mi trabajo es escribir loops.” Peter Steinberger dijo lo mismo desde el otro lado: “Ya no deberías estarle haciendo prompts a tus agentes de código. Deberías estar diseñando loops que les hagan prompts a tus agentes.”
Seré honesto con mis reservas desde el principio. Esto es temprano, la economía de tokens puede variar enormemente dependiendo de si tienes acceso abundante o restringido, y la preocupación por la calidad del output es real. Pero la forma del asunto es correcta, y una vez que la ves no puedes dejar de verla. Así es como funciona.
1. El Punto de Apalancamiento se Movió
Este es el modelo mental. Un loop es un objetivo recursivo: defines un propósito y el sistema itera hasta que ese propósito se cumple. Tú no conduces cada paso. Diseñas una pequeña máquina que encuentra el trabajo, lo distribuye, lo verifica, anota lo que está hecho y decide el siguiente paso. Luego dejas que esa máquina impulse a los agentes en lugar de hacerlo tú mismo.
Antes he escrito sobre las capas que sostienen esto. La ingeniería del harness consiste en dar forma al entorno en el que corre un agente individual. El modelo de fábrica es el sistema que construye el software. Loop engineering se sitúa un piso encima del harness: es el harness, pero corre según un calendario, genera helpers y se retroalimenta solo. El agente deja de ser algo que sostienes para convertirse en algo que tu sistema opera.
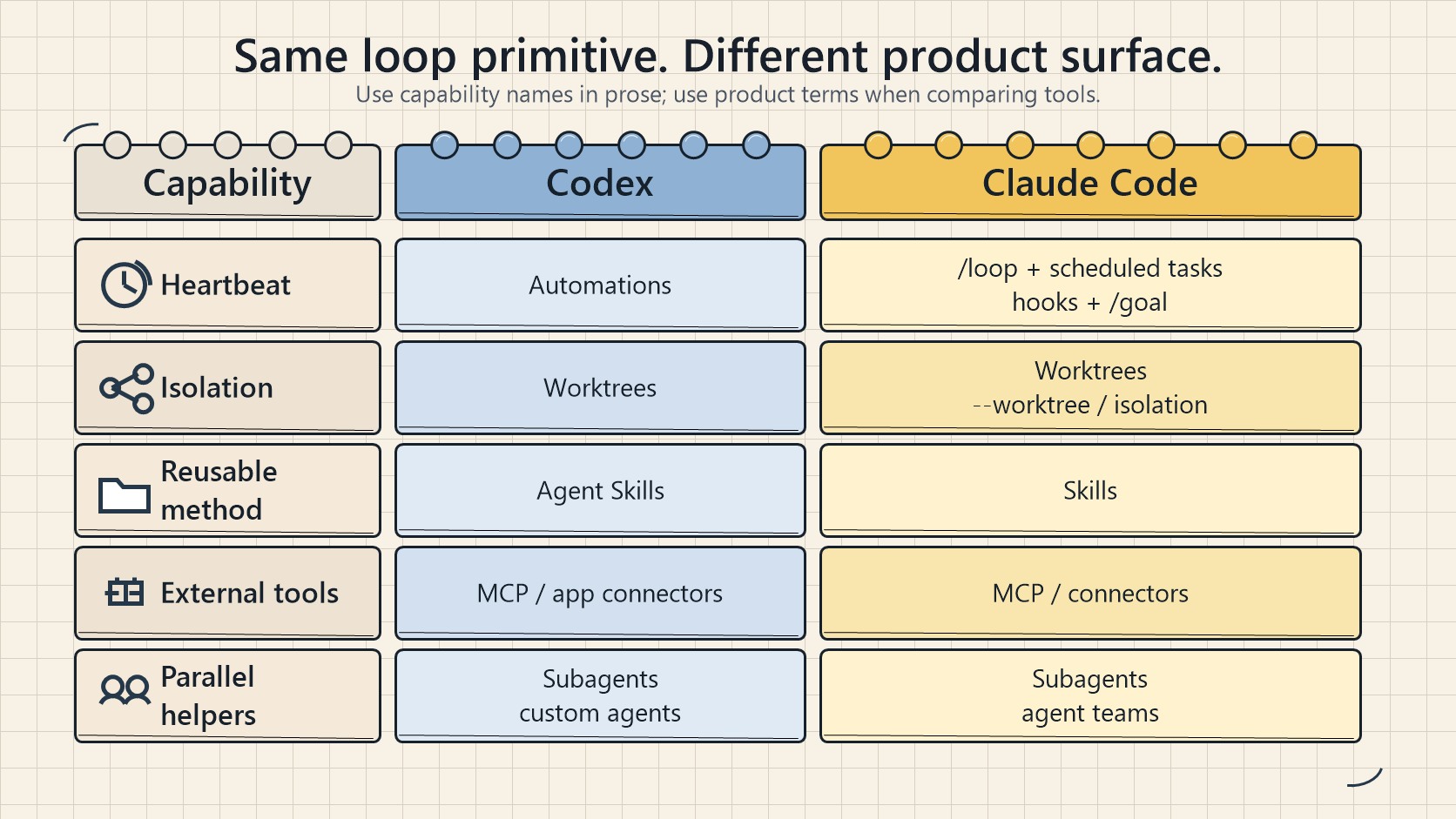
La sorpresa es que esto ya no es un problema de herramientas. Hace un año, si querías un loop, escribías un montón de bash y mantenías ese montón para siempre. Ahora las piezas vienen dentro de los productos. La lista de primitivas de Steinberger se mapea casi exactamente sobre la app de Codex, y casi igual sobre Claude Code. Una vez que notas que las formas son idénticas, dejas de discutir sobre cuál herramienta gana y empiezas a diseñar un loop que sobreviva cualquiera de las que estés usando.
[!important] El trabajo no se volvió más fácil. El punto de apalancamiento se movió. Antes gastabas tu habilidad escribiendo el prompt. Ahora la gastas diseñando el sistema que escribe los prompts, y verificando lo que ese sistema produce.
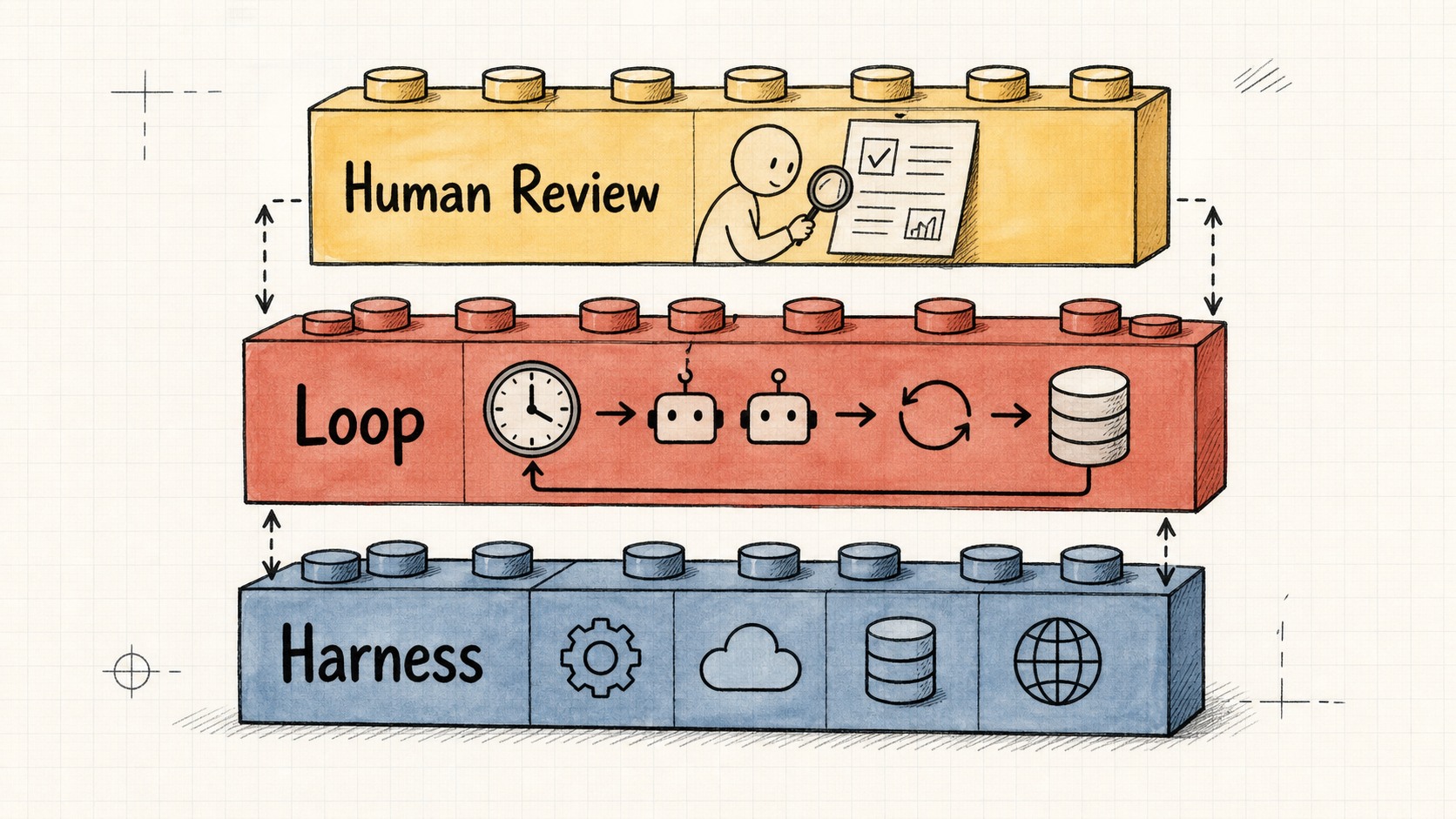
Loop engineering se sitúa un piso encima del harness: mismos componentes, pero corre con una cadencia, genera helpers y se retroalimenta solo.
2. Las Cinco Piezas, Más la que lo Sostiene Todo
Un loop funcional necesita cinco bloques constructivos y un lugar para recordar las cosas. Tanto Claude Code como Codex tienen las cinco ahora. Los nombres difieren aquí y allá, pero la capacidad es la misma. Los detalles son exactamente donde un loop se mantiene unido o se desintegra en silencio por todos lados.
Automations: el latido
Las automations son lo que convierte un loop en un loop real y no en una ejecución que hiciste una vez. Se activan según un calendario y hacen el descubrimiento y el triage por sí solas.
En la app de Codex creas una en la pestaña Automations: eliges el proyecto, el prompt, la cadencia y si corre sobre tu checkout local o un worktree en segundo plano. Las ejecuciones que encuentran algo llegan a una bandeja de entrada de triage; las que no encuentran nada se archivan solas. OpenAI las usa internamente para el trabajo recurrente que nadie quiere supervisar: triage diario de issues, resúmenes de fallos de CI, redacción de briefings de commits, búsqueda de bugs que alguien añadió la semana pasada. Una automation también puede llamar a un skill, lo que significa que disparas $nombre-del-skill en lugar de pegar un bloque enorme de instrucciones en un calendario que nadie va a mantener.
Claude Code llega al mismo lugar a través de scheduling y hooks. Corres un prompt o comando en un intervalo con /loop, programas una tarea cron, disparas comandos de shell en puntos del ciclo de vida del agente con hooks, o empujas todo a GitHub Actions para que siga corriendo después de que cierres la laptop. Misma idea: defines una tarea autónoma, le das una cadencia, dejas que los hallazgos lleguen a ti en lugar de ir a revisarlos tú.
Hay una segunda primitiva en sesión que vale la pena conocer. /loop vuelve a correr según una cadencia. /goal sigue hasta que una condición que escribiste es realmente verdadera, y después de cada turno, un modelo pequeño separado verifica si ya terminaste. El agente que escribió el código no es el que lo califica. Le das algo como “todos los tests en test/auth pasan y el lint está limpio”, y te vas. Codex tiene la misma primitiva, también llamada /goal, con pausa, reanudación y cancelación. La misma herramienta en ambos, que es el patrón de todo este tema.
Esta es la parte que saca el trabajo a la superficie. El resto del loop actúa sobre él.
Worktrees: para que lo paralelo no se convierta en caos
En el segundo en que corres más de un agente, los archivos empiezan a colisionar, y esa colisión se convierte en el modo de falla. Dos agentes escribiendo el mismo archivo es exactamente el mismo dolor de cabeza que dos ingenieros haciendo commit sobre las mismas líneas sin coordinarse.
Un git worktree lo resuelve. Es un directorio de trabajo separado en su propia rama, compartiendo el mismo historial de repo, de modo que las ediciones de un agente no pueden tocar el checkout de otro. Codex integra el soporte de worktrees directamente para que varios hilos accedan al mismo repo sin chocar entre sí. Claude Code te da el mismo aislamiento: git worktree, un flag --worktree para abrir una sesión en su propio checkout, y una configuración isolation: worktree que le asignas a un subagent para que cada helper tenga un checkout limpio que se auto-elimina al terminar.
Pero los worktrees eliminan la colisión mecánica, no a ti. Tu capacidad de revisión sigue siendo el techo. Eso decide cuántos agentes puedes correr en realidad, no la herramienta. A esto lo llamo el impuesto de orquestación, y es real.
[!warning] Los worktrees te permiten lanzar diez agentes en paralelo. No te permiten revisar diez agentes en paralelo. La herramienta escala el trabajo; no escala tu criterio. Lanza solo lo que puedas verificar de verdad.
Skills: para que dejes de reexplicar tu proyecto en cada sesión
Un skill es la forma de dejar de reexplicar el mismo contexto del proyecto en cada sesión. Ambas herramientas usan el mismo formato: una carpeta con un SKILL.md que contiene instrucciones y metadatos, más scripts opcionales, referencias y assets. Codex ejecuta un skill cuando lo llamas con $ o /skills, o automáticamente cuando tu tarea coincide con la descripción del skill. Esa última parte es la razón por la que una descripción concisa y directa supera a una ingeniosa. Claude Code funciona igual.
Los skills son donde la intención deja de costarte cada ejecución. Un agente empieza cada sesión desde cero, y rellenará cualquier vacío en tu intención con una suposición confiada. Eso es deuda de intención, y se acumula. Un skill es tu intención escrita hacia afuera: las convenciones, los pasos de build, el “no lo hacemos así por culpa de ese incidente”. Escrita una vez, en un lugar que el agente lee en cada ejecución.
Sin skills, el loop rederiva todo tu proyecto desde cero en cada ciclo. Con skills, se acumula. Una distinción que vale mantener clara: el skill es el formato de autoría; un plugin es cómo lo distribuyes. Cuando quieres compartir un skill entre repos o agrupar varios juntos, los empaquetas como plugin. Cierto en Codex, cierto en Claude Code.
Los nombres difieren, la capacidad es idéntica. Diseña el loop, no la herramienta. Sobrevive en cualquier producto que uses.
Connectors: para que el loop toque tus herramientas reales
Un loop que solo puede ver el sistema de archivos es un loop pequeño. Los connectors, construidos sobre MCP, permiten al agente leer tu issue tracker, consultar una base de datos, llamar a una API de staging o dejar un mensaje en Slack. Codex y Claude Code hablan MCP, así que un connector que escribiste para uno generalmente funciona en el otro sin modificaciones. Los plugins agrupan connectors y skills juntos, para que un colega instale toda tu configuración de una vez en lugar de reconstruirla de memoria.
Esta es la diferencia entre un agente que dice “aquí está el fix” y un loop que abre el PR, enlaza el ticket de Linear y notifica al canal cuando CI queda verde. Solo. Los connectors son la razón por la que el loop puede actuar dentro de tu entorno real en lugar de narrar lo que haría si pudiera.
Sub-agentes: mantén al que crea separado del que verifica
La decisión estructural más útil en un loop es separar al agente que escribe del agente que revisa. El modelo que escribió el código es demasiado generoso para calificar su propio trabajo. Un segundo agente con instrucciones distintas, a veces un modelo diferente, captura lo que el primero se convenció de que estaba bien.
Codex lanza subagents cuando se lo pides, los corre en paralelo y consolida los resultados en una sola respuesta. Defines los agentes como archivos TOML en .codex/agents/, cada uno con nombre, descripción, instrucciones y modelo y nivel de razonamiento opcionales. Tu revisor de seguridad puede ser un modelo potente con esfuerzo alto mientras que tu explorador es algo rápido y de solo lectura. Claude Code hace lo mismo con subagents en .claude/agents/ y equipos de agentes que se pasan el trabajo entre ellos. La división habitual en ambos: un agente explora, uno implementa, uno verifica contra el spec.
La razón por la que esto importa específicamente dentro de un loop es que el loop corre mientras no estás mirando. Un verificador en el que realmente confías es la única razón por la que puedes alejarte. Los subagents consumen más tokens, ya que cada uno hace su propio trabajo de modelo y herramientas, así que úsalos donde una segunda opinión vale el costo. Esto también es lo que hace /goal de Claude Code por debajo: un modelo nuevo decide si el loop terminó, en lugar del modelo que hizo el trabajo. La separación creador-verificador aplicada a la condición de parada en sí misma.
La memoria: la columna vertebral
Luego el sexto elemento: la memoria. Un archivo markdown, un tablero de Linear, cualquier cosa que viva fuera de la conversación individual y guarde qué está hecho y qué sigue. Suena demasiado simple para importar. Es el mismo truco del que depende todo agente de larga duración.
El modelo olvida todo entre ejecuciones, así que la memoria tiene que vivir en disco, no en el contexto. El loop corre. La conversación se cierra. El archivo de estado permanece. Sin él, la ejecución de mañana empieza desde cero y rediscute lo de ayer. Con uno, el loop retoma exactamente donde lo dejó.
3. Cómo se Ve un Loop Real
Junta las piezas y un solo hilo se convierte en un pequeño panel de control. Hay una estructura a la que vuelvo constantemente.
Una automation corre cada mañana contra el repo. Su prompt llama a un skill de triage que lee los fallos de CI de ayer, los issues abiertos y los commits recientes, y escribe sus hallazgos en un archivo markdown o en un tablero de Linear (la memoria). Para cada hallazgo que vale la pena atender, el hilo abre un worktree aislado y envía un sub-agente a redactar el fix. Un segundo sub-agente revisa ese borrador contra los skills del proyecto y los tests existentes. Los connectors permiten que el loop abra el PR y actualice el ticket. Todo lo que el loop no puede manejar llega a la bandeja de triage para mí.
El archivo de estado es la columna vertebral de todo. Recuerda qué se intentó, qué pasó, qué sigue abierto, para que la ejecución de mañana continúe en lugar de reiniciar.
Ahora mira lo que realmente hiciste ahí. Lo diseñaste una vez. No hiciste prompts a ninguno de esos pasos. Ese es el punto concreto de Steinberger, y es el mismo loop ya sea que lo construyas en Codex o en Claude Code, porque las piezas son las mismas piezas.
[!quote] “Ya no le hago prompts a Claude. Tengo loops que le hacen prompts a Claude y deciden qué hacer. Mi trabajo es escribir loops.” — Boris Cherny, Claude Code en Anthropic
4. Lo que el Loop Nunca Hará por Ti
El loop cambia el trabajo. No te elimina de él. Tres problemas se vuelven más agudos a medida que el loop mejora, no más suaves.
La verificación sigue siendo tu responsabilidad. Un loop que corre sin supervisión también es un loop que comete errores sin supervisión. La razón entera por la que separas el subagent verificador del creador es para que el “está listo” del loop signifique algo. Aun así, “listo” es una afirmación, no una prueba. La frase que sigo repitiendo: tu trabajo es enviar código que confirmaste que funciona. No código que un agente te dijo que funciona.
Tu comprensión se deteriora si lo permites. Cuanto más rápido produce código el loop que tú no escribiste, más grande se vuelve la brecha entre lo que existe y lo que realmente entiendes. Eso es deuda de comprensión, y un loop fluido la hace crecer más rápido a menos que leas lo que el loop produjo. La fricción que eliminaste era la misma fricción que te mantenía al día con tu propio codebase.
La postura cómoda es la peligrosa. Cuando el loop se ejecuta solo, es tentador dejar de tener opinión y simplemente aceptar lo que devuelve. Eso es rendición cognitiva. Y aquí está la trampa: diseñar el loop es el antídoto cuando lo haces con criterio, y el acelerador cuando lo haces para evitar pensar. La misma acción. El resultado opuesto. El loop no sabe cuál de las dos estás haciendo. Tú sí.
[!warning] Dos personas construyen el mismo loop y obtienen resultados opuestos. Una lo usa para moverse más rápido en trabajo que entiende profundamente. La otra lo usa para evitar entender el trabajo en absoluto. Las herramientas son neutrales. La intención no lo es.
5. Construye el Loop. Mantente como el Ingeniero.
Esto es una vista previa de cómo evoluciona el trabajo, y creo que es mayormente la dirección correcta. Pero te diré exactamente dónde me ubico después de correr estos patrones yo mismo: si no estuviera revisando el código, o si dependiera enteramente de loops automatizados para arreglar las cosas, la calidad de mi producto se degradaría. Me metería en un hoyo y seguiría cavando, un merge sin revisar a la vez.
Así que configura tus loops. Diseña la automation, escribe los skills, separa al creador del verificador, dale una memoria en disco. Pero no olvides que hacer prompts directamente a tus agentes sigue siendo efectivo para una enorme cantidad de trabajo. Esto no es una migración que abandona el prompting. Es una segunda marcha. La habilidad está en saber cuál estás usando.
Diseñar loops es más difícil que hacer prompt engineering, no más fácil. Esa es la parte que los titulares se pierden. Un prompt falla de forma ruidosa e inmediata. Un loop mal diseñado falla en silencio, durante horas, mientras no estás mirando, y te entrega un confiado “listo” sobre trabajo que nadie revisó de verdad. El punto de Cherny nunca fue que el trabajo se volviera más fácil. El apalancamiento se movió, y el apalancamiento corta en ambas direcciones.
Construye el loop. Pero constrúyelo como alguien que tiene la intención de seguir siendo el ingeniero, no solo el que aprieta el botón.