
Construí un SaaS Médico con IA. Después Me Hackearon. Acá Está el Caso de Estudio.
La primera noche que subí a producción el sistema de agendamiento médico de mi hermana, me acosté sintiéndome como un rey. A las 9am del día siguiente, el CPU de mi servidor estaba saturado al 300%, y alguien más estaba minando criptomonedas en mi hardware alquilado.
Pero esa es la mitad de la historia. Déjame retroceder.
Este es un caso de estudio sobre el SaaS que siempre quise construir, el que finalmente me encontró, y todo lo que rompí y aprendí para hacerlo funcionar. También es la historia de un Product Designer que pensaba que entendía software, y descubrió que internet es un lugar mucho más extraño y hostil de lo que cualquier archivo de Figma hubiera sugerido.
Una nota rápida antes de empezar: toda la data mostrada en este post es falsa. Las capturas están acá para ilustrar cómo se ve el sistema hoy, nada más.
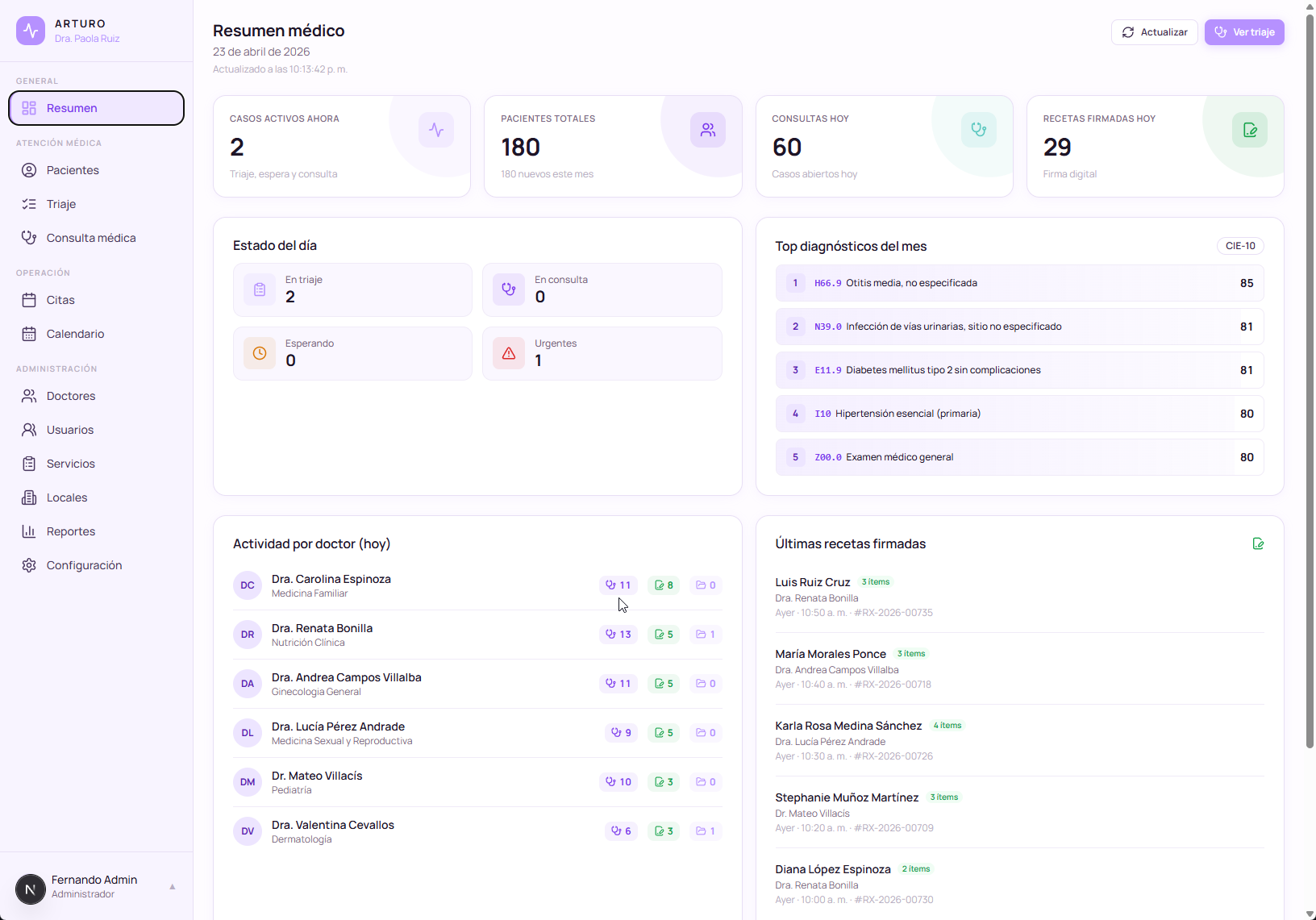
La barra de módulos de ArturoMed. Cada ítem de acá está conectado con todas las otras piezas del sistema.
1. Un Problema Que No Sabía Que Estaba Buscando
Había estado rondando la idea de un SaaS durante años. Todo el mundo tech en internet habla de lo mismo: construye el producto, gana tu MRR (Monthly Recurring Revenue, ingresos recurrentes mensuales), retírate con el crecimiento compuesto. Pero nunca tuve un problema que valiera la pena resolver. Las ideas llegaban y se iban, y ninguna se sentía como mía.
Entonces tuve una larga conversación con mi hermana, Dra. Paola Ruiz.
Ella tiene 1.7 millones de seguidores en TikTok como @bethruizmed. Es doctora. Por razones relacionadas tanto con su audiencia como con el sistema de salud ecuatoriano, empezó a ofrecer asesorías en línea sobre salud sexual y reproductiva. Como es trabajo de asesoría, no práctica clínica diagnóstica, puede atender personas en muchos países, no solo Ecuador. Resulta que ahí hay una brecha real, tanto en educación pública como en acceso a un médico que no te cobre un sueldo semanal por treinta minutos. Cabe mencionar: los médicos generales en Ecuador tienen fama de batallar para encontrar trabajo estable, así que este tipo de práctica independiente también es una forma de rearmar una carrera en tus propios términos.
Ella encontró el problema, lo resolvió, y estaba funcionando.
Hasta que no lo hizo.
No en el sentido empresarial. El negocio estaba floreciendo. Pero se topó con el primer techo que todo operador exitoso en solitario enfrenta: el éxito sin sistemas colapsa sobre sí mismo. Ella es una doctora excelente. No es gerente de proyectos. No está gestionando operaciones. Cada reserva de cita, cada confirmación de pago, cada seguimiento estaba viviendo dentro de hilos de WhatsApp Business. Se estaba ahogando en su propio pipeline.
Eventualmente contrató a mi otra hermana, Dra. Isabel Ruiz, también doctora, como asistente de operaciones a tiempo parcial. Básicamente una secretaria, solo para mantenerse a flote.
Ahí fue cuando entré yo. Hice una oferta: “¿Qué tal si dejamos de apagar incendios con WhatsApp y te construyo el sistema?”
Le había construido el sitio web meses atrás. Los leads ya estaban fluyendo. Automatizar el pipeline era el siguiente paso obvio.
2. Los Cuatro Pilares de Cualquier Producto Real
Antes de escribir una sola línea de código, me obligué a pensar sobre la forma de lo que estaba construyendo. Una cosa que había aprendido en algún lugar: todo producto real tiene aproximadamente cuatro o cinco componentes esenciales.
- Un frontend. Lo que el usuario realmente toca.
- Un backend. La lógica que decide qué sucede.
- Un sistema de autenticación. Para que la gente sea quien dice ser.
- Un sistema de pagos. Porque esto es un negocio, no un hobby.
- Una base de datos. Porque nada importa si no persiste.
Esto suena obvio. No lo es. La mayoría de “MVPs construidos con IA” que ves en línea son la mitad de un frontend con un backend de fantasía y cero persistencia. Se ven bien en demostraciones y mueren en el momento en que aparece un segundo usuario. Si quieres entregar algo real, los cinco pilares necesitan estar de pie al mismo tiempo.
Mi hermana pagó mi suscripción de Claude Pro ($100 al mes) y la puse a trabajar. En serio.
Decisiones técnicas
Refactoricé su sitio web existente en React, y construí el backend en TypeScript con Postgres. Stack estándar, nada exótico. La opción más interesante fue la infraestructura: decidí empacar toda la aplicación (frontend, backend, base de datos) dentro de un único contenedor Docker con tres partes lógicas.
Esto no es lo que la mayoría de tutoriales te dicen que hagas. La mayoría empujan hacia microservicios, una base de datos gestionada, y algún orquestador. Para un deploy privado como el mío, eso es overkill y una carga de mantenimiento innecesaria. Un contenedor significaba un deploy, un backup, una sola cosa en la que pensar. Me mantuvo en movimiento.
En el camino aprendí bastante de lo que no sabía que necesitaba aprender: correr [[Claude Code]] con agentes en segundo plano, estructurar una suite de tests de verdad, separar ambientes, pensar en migraciones como ciudadanas de primera clase. Estaba aprendiendo en vivo, con un usuario real en juego que esperaba que la cosa funcionara.
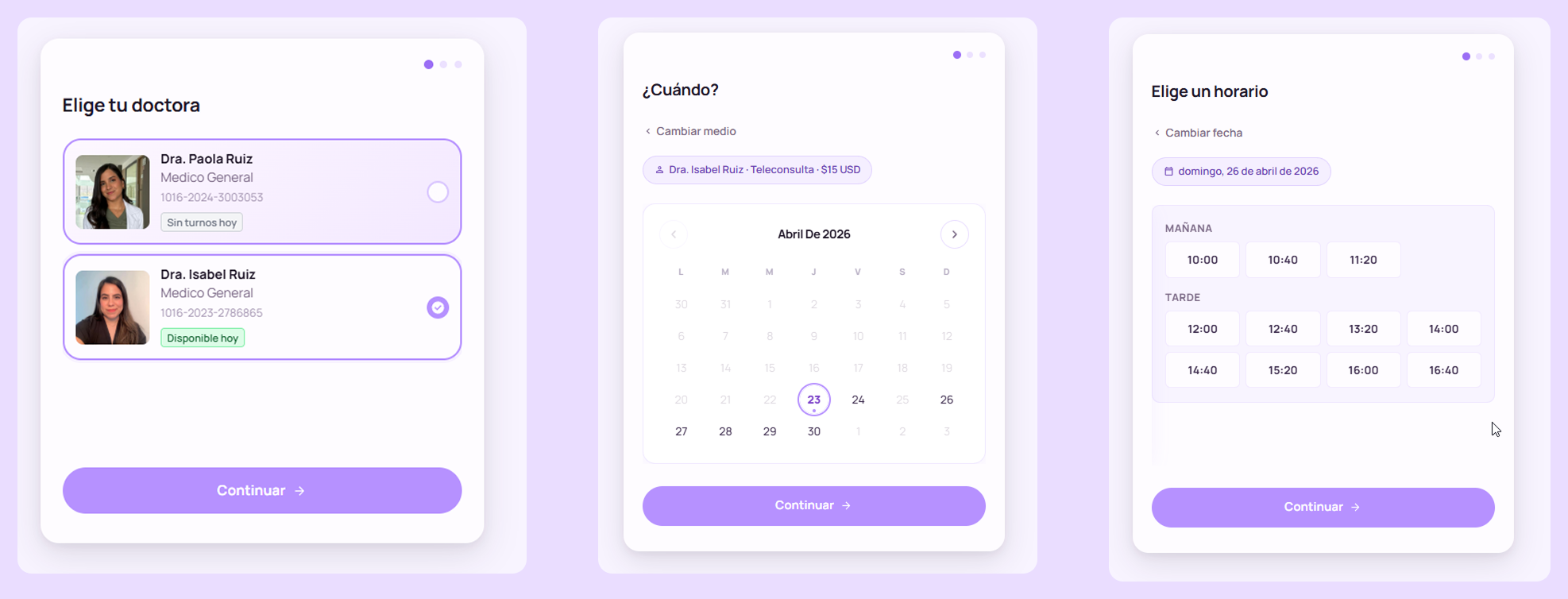
El flujo de citas. La cosa que realmente me importaba entregar. Llegar a este punto significó luchar contra todo lo descrito en la siguiente sección.
3. La Noche Que Me Hackearon
El sistema llegó a “más o menos funcional”. Lo sometí a un fin de semana de pruebas manuales. Estaba orgulloso. Era lo más cercano a un producto real que había construido con mis propias manos.
Lo desplegué a producción. Porque el sistema es privado (solo para ella), no esperaba mucho drama. Me acosté.
La mañana siguiente, revisé el dashboard del servidor. El CPU estaba corriendo al 300%. Había estado al 300% durante once o doce horas seguidas.
Ahora bien, soy un genio de la seguridad informática (para nada). No tenía idea de qué estaba pasando. Así que le pasé a Claude los logs y procesos del servidor y le pedí que descubriera qué diablos estaba sucediendo.
El diagnóstico llegó rápido: alguien estaba corriendo un miner de criptomonedas en mi servidor. Monero, específicamente. Estaban usando mi CPU para imprimir dinero para ellos, y mi factura de hosting pagaba la electricidad.
Pero lo interesante no era el miner. Era cómo habían entrado.
La causa real: Next.js tenía un hueco de seguridad crítico, y alguien en internet lo encontró.
Next.js es el framework sobre el que corre mi dashboard. La versión que tenía desplegada contenía un bug conocido y documentado que permitía a cualquiera en internet mandar una petición específicamente construida y correr su propio código en mi servidor. Sin password. Sin cuenta. Sin credenciales robadas. Solo sabiendo la dirección del servidor.
Los huecos de seguridad como este se puntúan del cero al diez según qué tan peligrosos son. El mío era un diez. El parche llevaba semanas publicado. Yo no estaba en la versión parchada.
El ataque. Minutos después de que subí el servidor, algo en internet empezó a hurgar. Primero reconocimiento para averiguar qué software estaba corriendo. Después, segundos después de confirmar que tenía la versión vulnerable, disparó el exploit. En menos de un minuto, el miner estaba vivo dentro de mi contenedor, corriendo como el usuario con más privilegios, quemando CPU para la wallet de alguien más.
Por eso el CPU estuvo al tope durante once horas mientras yo dormía.
Las tres cosas que hice mal.
Primero, asumí que la IA que estaba escribiendo mi código iba a elegir las últimas versiones seguras de los frameworks que usaba. No lo hizo. Eligió versiones más viejas, genuinamente publicadas por Vercel, la empresa detrás de Next.js, pero ya marcadas con huecos de seguridad conocidos que la propia empresa había pedido actualizar. “Genuino” y “seguro” no son la misma palabra.
Segundo, mi pipeline de deploy estaba construyendo el software directamente en el servidor de producción. Era la forma fácil de lanzar, pero significaba que el build y la app en vivo vivían en la misma máquina. Cualquier cosa maliciosa que corriera durante un build tenía el mismo acceso que la app en vivo: passwords de base de datos, API keys, todo.
Tercero, mi build no era estricto con las versiones. Podía usar silenciosamente versiones distintas a las que mi código había sido probado, que es una forma confiable de arrastrar cambios que no pediste. No fue como aterrizó este ataque específico, pero era una puerta abierta esperando al siguiente.
Tres errores. Un hueco conocido. Once horas de minería de alguien más. Una mañana muy molesta.
[!warning] Correr software sin parchar en internet es el ataque Si hay un hueco de seguridad conocido en cualquier pieza de tu stack y estás en una versión sin el parche, todo lo demás es ruido. El Bosque Oscuro te encuentra escaneando cada IP de internet en loop. El tiempo entre “mi servidor está vivo” y “alguien está probando exploits conocidos contra él” se mide en horas. Parchar primero. Todo lo demás después.
4. Reconstruyendo Con Cicatrices
Pasé los siguientes dos días haciendo lo que debería haber hecho en el día cero. La lista se hizo larga rápido.
Parchar Next.js, en todas partes, el mismo día. Las dos versiones en mi stack (el dashboard en 15.2.3, el sitio de marketing en 14.2.35) subieron a 16.2.4, que parcha CVE-2025-55182. El fix es el upgrade.
Rotar todas las credenciales que el contenedor tocó. Password de base de datos, NextAuth secret, private key de la service account de Google, OAuth client secret de Google, API key de Resend, cron secret. Si el miner corrió como root dentro del contenedor, /proc/1/environ era legible. Cada variable de entorno se considera filtrada.
npm install queda prohibido en Dockerfiles. Reemplazado por npm ci, que falla el build si package.json y package-lock.json no coinciden en vez de resolver silenciosamente un árbol de dependencias diferente.
Los contenedores bajan a un usuario no-root. Se crea un usuario app en el build y USER app corre antes del CMD. Cuando pase el próximo RCE (y siempre pasa alguno eventualmente), el atacante aterriza en una shell que no puede tocar procesos root ni el filesystem del host.
Geo-blocking en el firewall. La audiencia de Paola es las Américas y parte de España, así que los puertos 80 y 443 están bloqueados para todos los demás. Unos 50,000 CIDRs permitidos vía feeds de ipdeny, el resto del planeta denegado. El tráfico de probing cayó 90% de la noche a la mañana.
Blocklist de IPs maliciosas. Feeds de FireHOL Level 1, Spamhaus DROP, y Feodo Tracker se pullean diariamente. Unas 4,500 IPs que están activamente atacando infraestructura de otra gente ahora mismo no llegan a la mía.
Rate limits de nginx, por endpoint. Login a 5 req/min, API pública a 30 req/s, páginas generales a 20 req/s. Un probe de fuerza bruta alcanza el límite en segundos.
fail2ban, tres jails. Uno mira los logs de nginx por el IOC del RCE de Server Action (Failed to find Server Action), uno por violaciones de rate-limit, uno por brute force en SSH. Primera hora después del redeploy, tres IPs ya baneadas.
npm audit --audit-level=high filtra el deploy. Cualquier CVE de alta severidad en cualquier dependencia bloquea el pipeline. Auditorías verdes son un requisito, no una notificación.
Dependabot activado. PRs semanales para npm, mensuales para Docker y Actions. Las versiones se revisan solas y abren pull requests contra mí.
Build fuera del servidor de producción. El pipeline ahora compila en un runner efímero de GitHub Actions, corre tests, corre npm audit, y solo entonces pushea una imagen Docker. El único trabajo del servidor es docker pull, reiniciar, y correr migraciones SQL si el schema cambió. Nada más.
Ese último es el cambio que más quiero subrayar. Cuando separas el ambiente de build del ambiente de runtime, limitas el radio de explosión de una dependencia comprometida. Los ataques de cadena de suministro siguen sucediendo, pero se ejecutan dentro de un runner desechable que se destruye después de cada build, no dentro de la máquina que sostiene tus secretos de producción.
El Bosque Oscuro
Si has leído El Problema de los Tres Cuerpos de Liu Cixin, conoces la teoría del Bosque Oscuro. En el libro, el universo está lleno de civilizaciones que permanecen silenciosas porque anunciar tu presencia es una invitación a ser destruido. Todos están escuchando. Nadie quiere ser escuchado primero.
Internet es el Bosque Oscuro.
El ruido que nunca escuchas desde dentro de tu cómodo localhost es el ruido de millones de bots y escáneres haciendo ping a cada IP, cada puerto expuesto, cada firma de servicio conocida, buscando a alguien descuidado. En el momento en que expones algo que se ve mal configurado, algo ahí afuera se da cuenta.
Tenía un servidor de $20/mes. Me atacaron a las pocas horas de estar en línea.
Ahora imagina la atención que recibe tu servidor si corre en 200GB de RAM y se ve apetitoso. El Bosque Oscuro no es metafórico. Es realidad operacional, y cualquiera que despliegue algo a una IP pública debería tratarlo así desde el día uno.
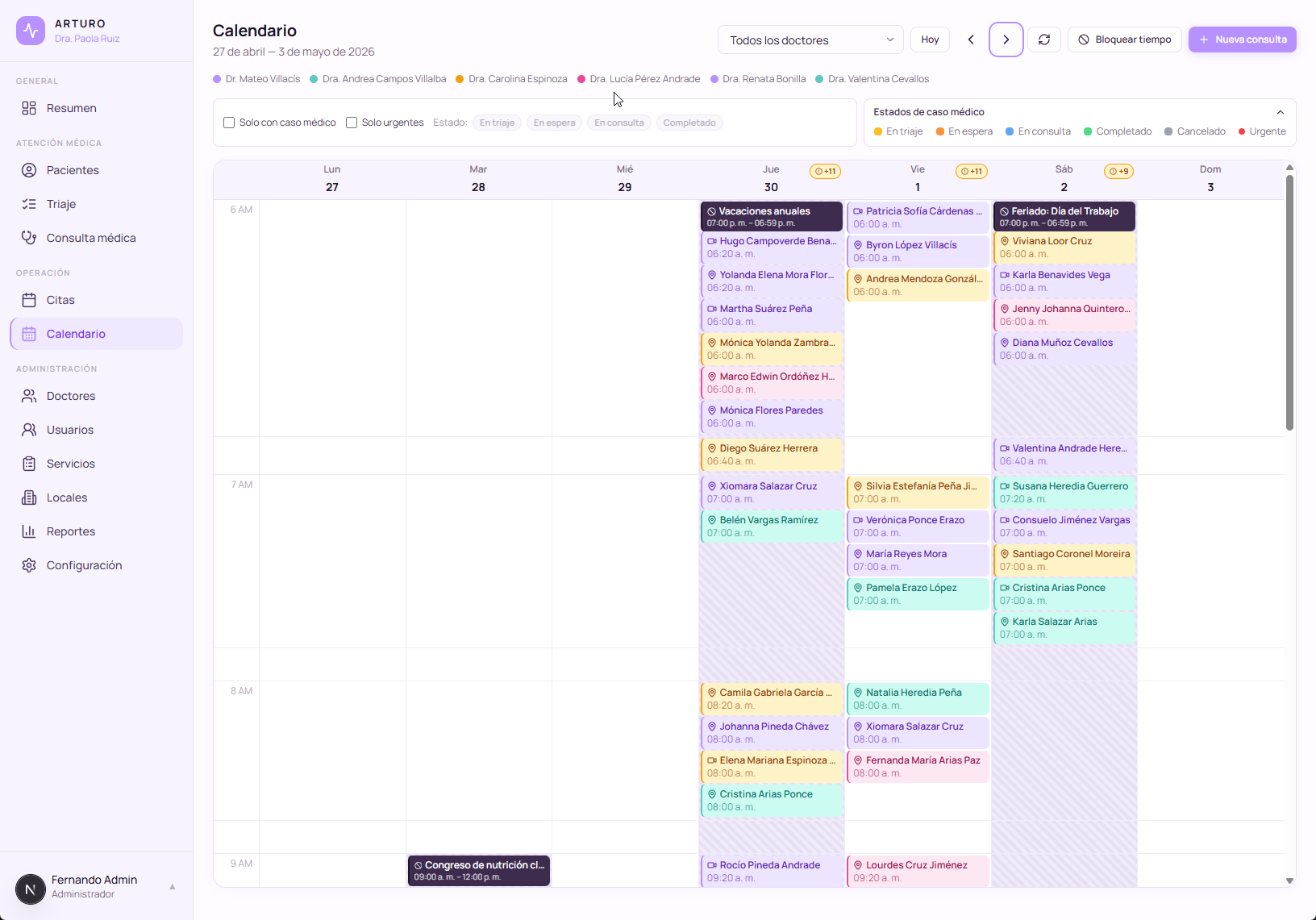
El módulo de calendario con bloqueo de tiempo. La columna vertebral sin glamour de cualquier plataforma de agendamiento que funcione.
5. La Noche de Kimi 2.6
Algunas semanas después del incidente del cryptominer, con el sistema estable, endurecido, y corriendo silenciosamente en producción, algo inesperado me cayó del cielo.
Cline estaba ofreciendo acceso gratuito a Kimi 2.6, el agente de codificación de Moonshot. De lo que había leído, rinde sorprendentemente cerca de Opus 4.6 en ciertas clases de tareas a una fracción del costo. Para un sistema como el mío, donde la arquitectura ya estaba establecida y principalmente necesitaba volumen de scaffolding, no decisiones arquitectónicas profundas, valía la pena probarlo.
Abrí una rama nueva. Le di al agente el set de permisos completo: sistema de archivos, instalación de paquetes, ejecución, todo. Le dije lo que quería: no otra herramienta de agendamiento para un solo doctor, sino una plataforma completa de operaciones para una clínica pequeña. Dashboard de resumen, citas, calendario, doctores, servicios, locales, reportes, configuración, y encima la superficie clínica: pacientes con historia, enfermeras, triaje. Cada módulo conectado con todos los demás. Después me fui a dormir.
Me desperté con un sistema funcionando. Lo bauticé ArturoMed, en honor a mi abuelo Arturo.
No “un prototipo”. No “un esqueleto”. ArturoMed tenía los módulos implementados, schemas definidos, rutas conectadas entre ellos, roles separados, y suficiente estructura como para pasar los siguientes días con Claude puliendo detalles en vez de escribir la base desde cero.
Y el punto de ArturoMed no es que cada módulo exista de forma aislada. El punto es que se hablan entre ellos. El perfil de un doctor se conecta a los servicios que ese doctor ofrece, a los locales donde atiende, a los slots del calendario que tiene bloqueados, a los reportes que resumen su mes. Un servicio se conecta a los locales que lo alojan y a los doctores que lo entregan. El calendario agrega a través de doctores y locales. Los reportes cortan por cualquier dimensión que te importe. ArturoMed está diseñado para una clínica, no para un solo profesional.
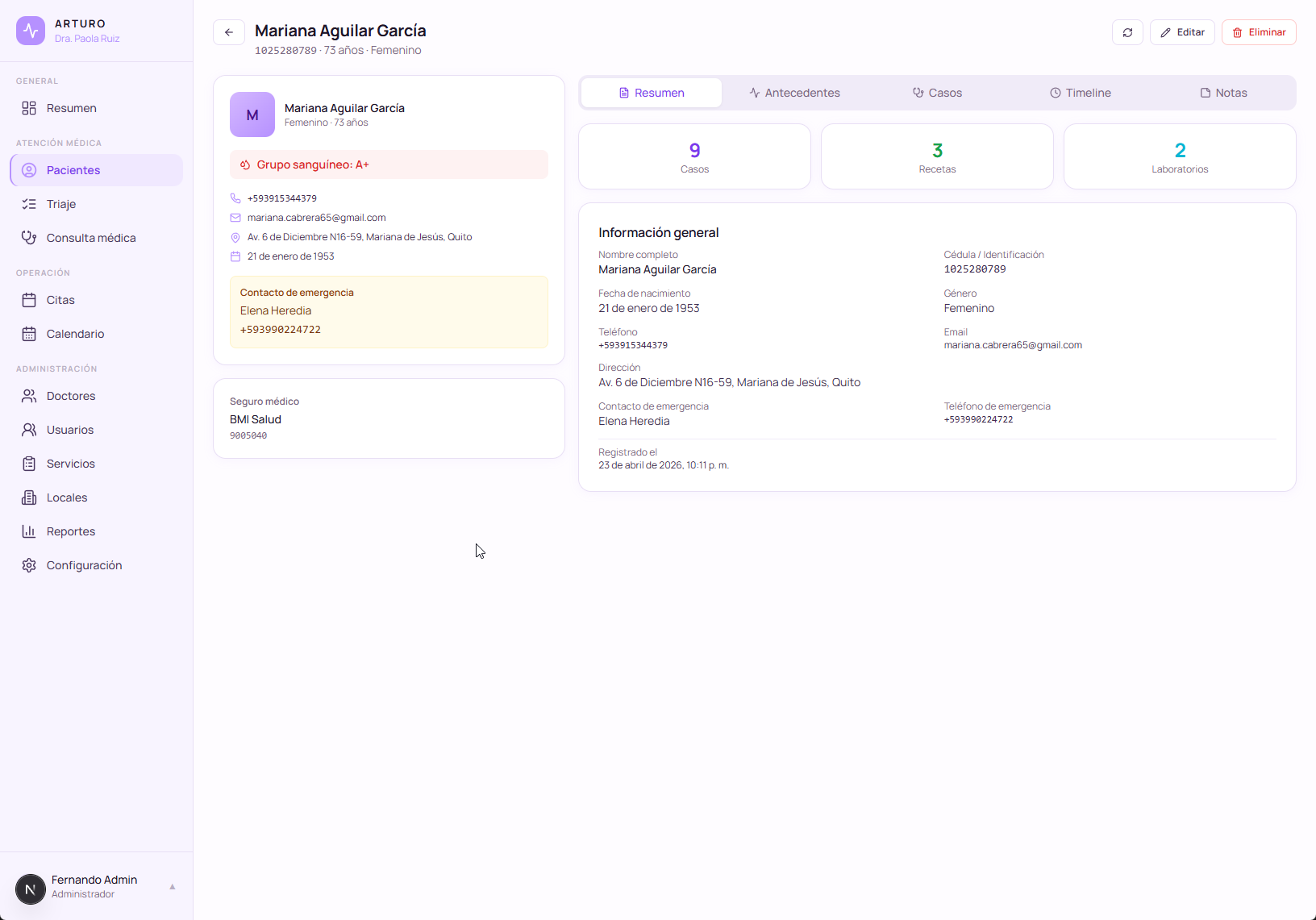
El módulo de paciente con historial clínico, construido durante la noche y refinado durante la semana siguiente. Un módulo de ArturoMed, conectado con todo lo demás en el sistema.
A este punto razonablemente podría acercarme hoy a una práctica pequeña y decirles: “Acá tienen una plataforma completa de operaciones. Corran su clínica con esto.” Y aguantaría.
Pero la parte clínica todavía no se la estoy entregando a nadie. Ni siquiera a Paola. Acá está el por qué.
Lo que Paola tiene corriendo en producción es únicamente la capa de agendamiento automático. Los pacientes reservan citas desde su sitio web, el sistema confirma, el calendario se actualiza, y listo. Nada de historia clínica, nada de notas de triaje, nada de datos médicos sensibles. Solo horarios de cita y datos básicos de contacto. ArturoMed vive en una rama en mi laptop, esperando.
La medicina es uno de los dominios más regulados del planeta, y Ecuador implementó su Ley de Protección de Datos en los últimos años, similar en espíritu a GDPR, adaptada a nuestro contexto. Las restricciones de privacidad alrededor de datos de pacientes son serias, y “construí esto en un fin de semana con IA” no es una defensa cuando se filtra el historial clínico de un paciente. Encima de la ley de datos, hasta donde entiendo, también hay un proceso formal con el Ministerio de Salud Pública (MSP) para cualquier plataforma que maneje historias clínicas, que es una conversación aparte de varios meses.
Así que ahora mismo estoy en la capa de compliance. Controles de acceso. Logs de auditoría. Encriptación de datos en reposo. Políticas de retención. Separación de roles entre vistas de doctor, enfermera, y admin. El trabajo que no se ve glamoroso en un video de demostración pero que determina si un producto tiene permiso legal para existir. Los módulos clínicos llegan a Paola solo cuando ese trabajo esté hecho y el panorama regulatorio esté claro.
6. Lo Que Realmente Aprendí
Esta es la parte del caso de estudio que me gustaría que alguien más me contara, así que voy a intentar ser honesto al respecto.
Un respeto profundo por los desarrolladores pre-IA
Ahora mismo estoy parado sobre unas 20,000 a 30,000 líneas de código para lo que es, en esencia, una hoja de Excel glorificada con un calendario encima. Construí esto con IA acelerándome en cada paso. Y aun así se me hizo enorme.
Si esto es lo que toma para una plataforma de agendamiento pequeña, ¿qué toma para correr un hospital? Inventario, laboratorios, farmacia, nómina, flujos de emergencia, multi-sede, multi-especialidad, integraciones legacy. Antes miraba el software médico empresarial y me parecía inflado. Ya no. Creo que la gente que lo mantiene merece una ovación de pie.
localhost es una mentira
Todo funciona en localhost. Todo.
En el momento en que lo pones en internet, con usuarios reales, autenticación real, latencia de red real, atacantes reales, descubres cuánto te estaba protegiendo tu ambiente de desarrollo. El salto de “funciona en mi máquina” a “funciona en producción para otros humanos” es el salto que la mayoría de proyectos construidos con IA nunca hace realmente.
Vibe coders, aprendan RLS
Si estás vibe coding un SaaS con una base de datos compartida, tienes que entender Row Level Security (RLS, Seguridad a Nivel de Fila). Sin ella, cualquier usuario autenticado potencialmente puede consultar datos de cualquier otro usuario. Esto no es una preocupación teórica. Es el comportamiento por defecto de la mayoría de configuraciones de base de datos a menos que explícitamente configures permisos.
RLS es la diferencia entre “cada usuario ve sus propios datos” y “bienvenido a la demanda colectiva”.
No todo npm install es seguro
Piensa dos veces antes de ejecutar npm install en cualquier cosa que no venga de un paquete por el que personalmente responderías. Los ataques de cadena de suministro son reales y están acelerándose. El cryptominer que atacó mi servidor no llegó por un email de phishing. Llegó a través de una dependencia transitiva de un framework importante, invisible para cualquiera que no estuviera específicamente buscándola.
Esta es la parte del desarrollo moderno de la que nadie quiere hablar, porque socava todo el ethos de “muévete rápido, importa todo”. Pero es la realidad.
Playwright cambió mi vida de pruebas
La última lección es más operacional que de seguridad. Antes dejaba que la IA probara mi app manejando un browser a través de MCP (Model Context Protocol). Funcionaba, pero era salvajemente costoso. Cada paso en la UI comía tokens, y una corrida completa de tests podía quemar un trozo serio de mi presupuesto diario de contexto.
Después aprendí Playwright, el framework de automatización de browser. Testea todo (cada botón, cada llamada a API, cada cambio de estado) de forma programada, sin un LLM en el loop. Ahora tengo tests end-to-end automatizados que corren sobre todo el sistema, mientras el LLM se reserva para las tareas que realmente necesitan inteligencia.
Antes de Playwright, los tests se sentían como la misión secundaria de Claude que me drenaba el presupuesto de la misión principal. Después de Playwright, los tests se convirtieron en infraestructura.
[!important] El patrón debajo de todo esto La IA abre puertas. No reemplaza el rigor. Te expone a una superficie (seguridad, infraestructura, compliance) que antes, como diseñador, no hubieras necesitado pensar. La disciplina es saber que esa superficie existe y elegir aprenderla.
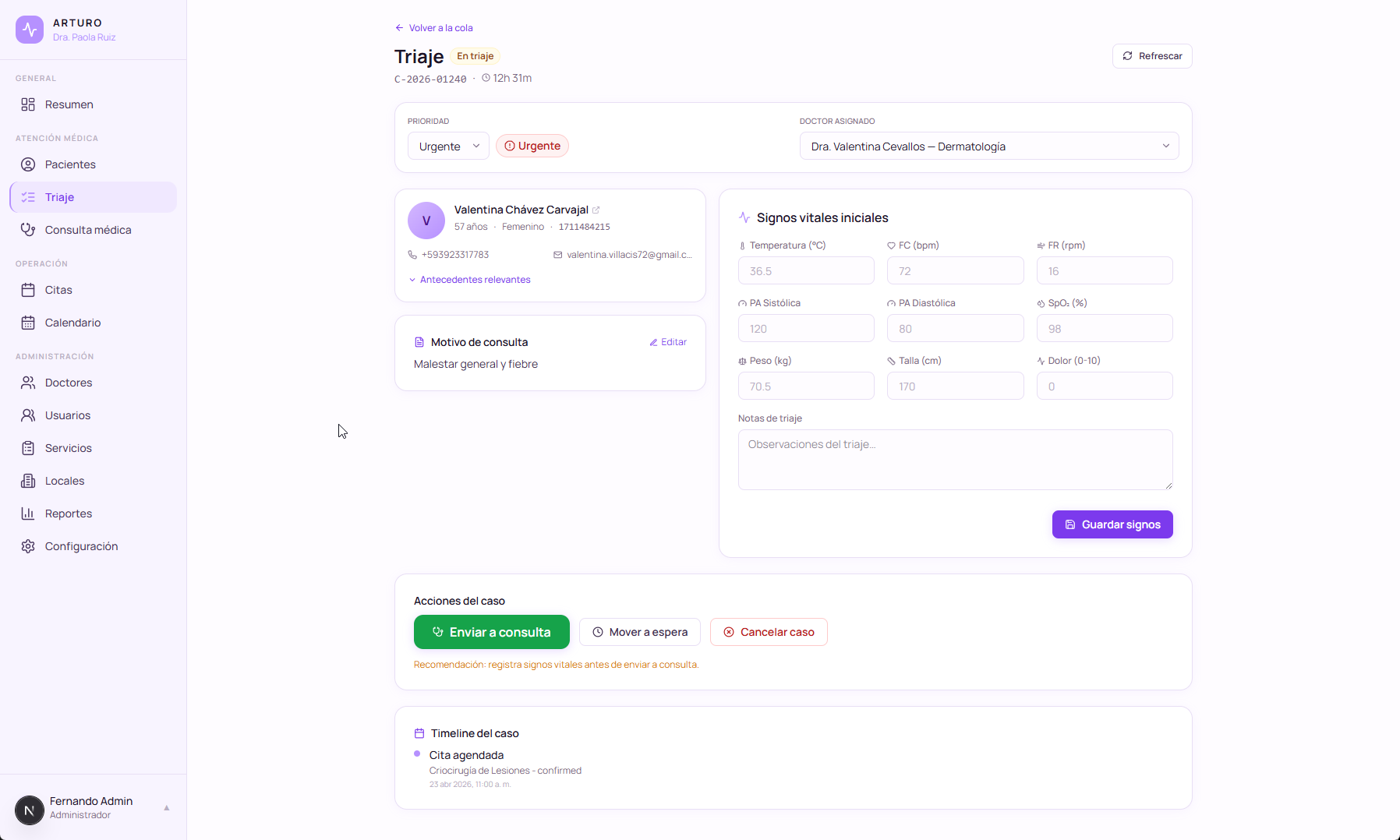
Dónde está el sistema hoy. Trabajo de compliance aún en progreso, pero operacionalmente completo. Todos los datos mostrados son sintéticos.
7. A Dónde Va Esto Después
Mis dos hermanas están notablemente más tranquilas estos días. Paola ya no se ahoga en agendamiento. Isabel ya no se quema persiguiendo hilos de WhatsApp. Los clientes se agendan solos desde el sitio web, el sistema confirma automáticamente, el calendario refleja la realidad. Tienen CRUD sobre las piezas que realmente necesitan (citas, servicios, ventanas de disponibilidad), más bloqueo de tiempo para cuando cualquiera de ellas necesita desconectarse. Nada de esto toca datos médicos: la versión en vivo es solo la capa de agendamiento automático, justamente porque el compliance aún no está.
La forma del equipo también cambió en el camino. Isabel empezó como apoyo administrativo, pero con el agendamiento corriendo solo, ahora tiene tiempo de tomar sus propias asesorías, y cubre los espacios de Paola cuando Paola no puede. Recién está construyendo su presencia online, así que si quieres seguir a una doctora construyendo su práctica activamente, @draisabelruiz en Instagram es donde la vas a encontrar.
Los hitos que me entusiasman vienen después, esperando a que se resuelva el panorama de compliance y MSP: búsqueda de historia clínica, recordatorios automatizados, mensajería más inteligente, y probablemente resúmenes de sesión generados por IA para que la doctora revise (no para reemplazar su juicio, solo para ahorrarle treinta minutos al día en documentación).
Si tuviera que comprimir toda esta historia en una sola frase para otro diseñador que esté pensando en construir algo real, sería esta:
Ten curiosidad.
Ten curiosidad sobre la tecnología que vive debajo de tus interfaces. Ten curiosidad sobre qué hace realmente que un sistema sea seguro, no solo sobre qué lo hace bonito. Pregúntale a tus desarrolladores cómo funciona. Pregúntales qué se rompe. Pregúntales qué les da miedo en producción. Entiende el pipeline de punta a punta. Porque los diseñadores estamos más cerca que nunca de poder entregar productos completos, y la brecha entre “puedo diseñar esto” y “puedo entregar esto” hoy depende principalmente de si estamos dispuestos a aprender la máquina.
Probablemente esto no sea mi magnum opus. Estoy demasiado al inicio de mi carrera para llamarle así a cualquier cosa. Pero es lo más orgulloso que he entregado hasta ahora, y es lo primero que he construido que cambió la realidad operativa de gente que amo.
Las capturas en este post muestran el sistema cargado con datos sintéticos, porque los datos reales pertenecen a pacientes reales, y todo el punto del trabajo de compliance es que nunca los veas.
Si eres una empresa o un operador en solitario buscando un Product Designer con experiencia real en UX/UI y gusto por entregar cosas que realmente corren en producción, estoy abierto a contratos. LinkedIn es el mejor lugar para contactarme.
Contrátame en LinkedIn →Y si quieres aprender las técnicas que uso, cómo opero entre diseño, herramientas de IA, y entrega de sistemas reales, doy un workshop con Xperience, una empresa de capacitación aquí en Ecuador especializada en educación de UX y Producto. La última cohorte salió con algunos de los mejores testimonios que he recibido.
Únete al workshop →